//
Assistants to Responses API: A Migration Field Guide

TL;DR
OpenAI is sunsetting the Assistants API in 2026. Here is a tested migration plan to the Responses API - code, state, threads, tools, every cliff I hit, in order.
Official Sources
| Topic | Primary source |
|---|---|
| Assistants deprecation | OpenAI deprecations and Assistants API (v2) FAQ |
| Migration guide | Assistants to Responses API migration |
| Responses API reference | Responses API object reference |
| Data retention and controls | Your data and retention |
Last updated: May 31, 2026. Verify details against the official docs before you cut over production traffic.
The Deprecation Timeline
OpenAI confirmed the Assistants API deprecation on their platform deprecations page and published a migration guide to the Responses API. If you are running production code against client.beta.threads.*, treat this as a scheduled migration, not a someday rewrite.
For the design side of the same problem, read OpenAI Codex: Cloud AI Coding With GPT-5.3 with OpenAI vs Anthropic in 2026 - Models, Tools, and Developer Experience; they show how agent-generated interfaces fail and how to give coding agents better visual constraints.
If you are running production code against client.beta.threads.* today, you have homework. I had a 14-month-old Assistants codebase running newsletter automation, customer support triage, and a chunk of internal ops. Last weekend I migrated all of it. This is the field guide - every cliff I hit, in order, with the code diffs that worked.
For the visual walkthrough including the eval harness I used to gate the cutover, see the DevDigest YouTube channel.
If you want a broader map of the OpenAI agent surface, start at /compare, then follow the OpenAI decision paths from AI coding tools pricing and the pricing hub.
Conceptual Diff: Threads vs. State
The Assistants API was server-stateful. You created a thread, posted messages, kicked off runs, polled for completion, and OpenAI held the conversation history. Your code did not own the state.
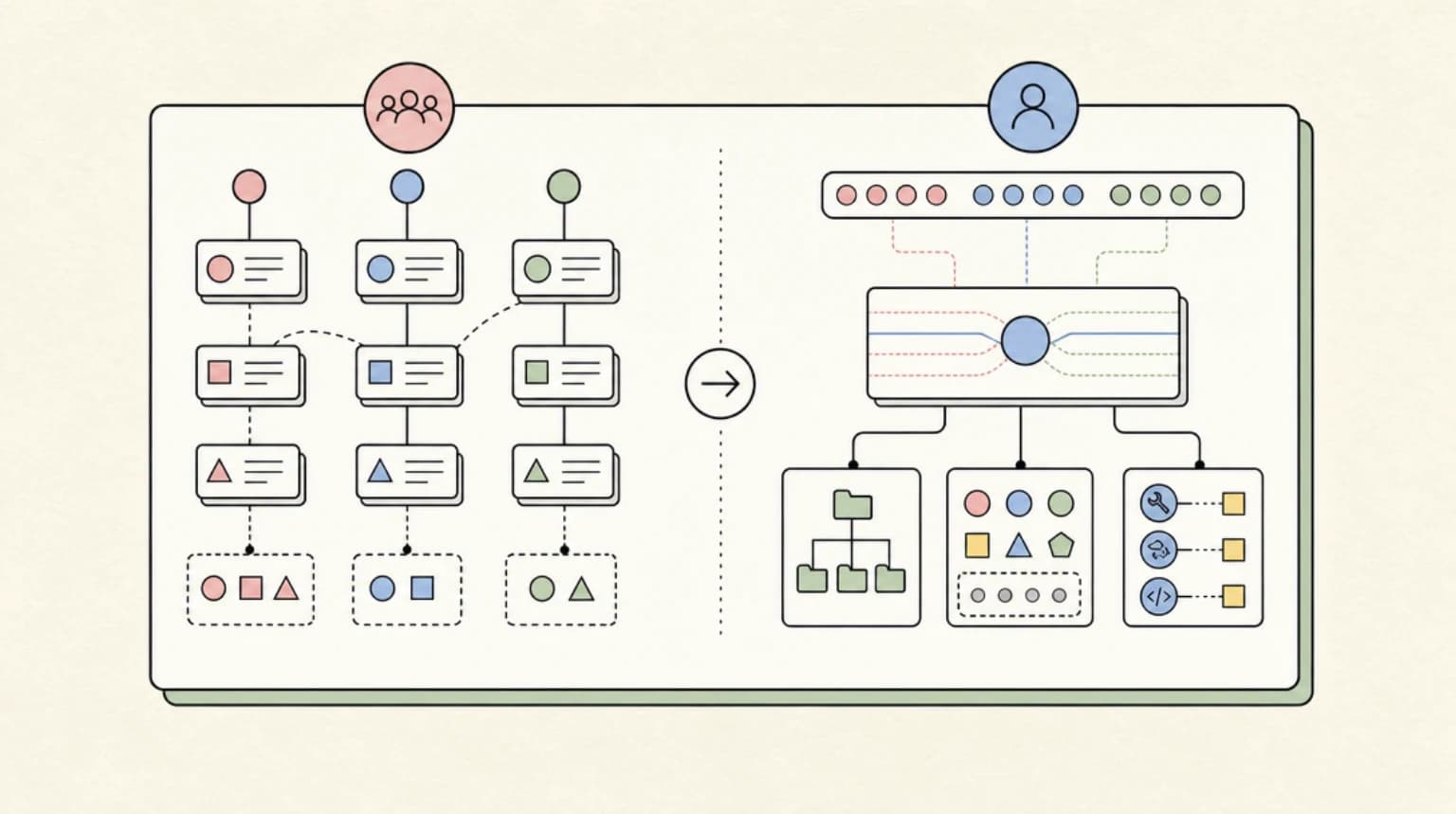
The Responses API is client-stateful by default, server-stateful by opt-in. Each call returns a response.id. You pass previous_response_id on the next call to get continuity. The server stores the chain for 30 days. After that, you reconstruct from your own DB or pass the message array explicitly.
This is the right design - server-only state was a footgun for compliance, debugging, and multi-region - but it changes how you think about every conversation:
| Assistants | Responses |
|---|---|
threads.create() | nothing - just call responses.create |
threads.messages.create() | include in input array |
runs.create() + poll | responses.create() returns synchronously or streams |
run.required_action | response.required_action (similar but flatter) |
assistants.create() | prompts + system messages + tools per call |
The big mental shift: there is no assistant object anymore. The "assistant" is your prompt template + tool list + model config, which you supply per call. This is why I version mine in Promptlock - the prompt is now a first-class artifact in your repo, not a row in OpenAI's database.
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools - delivered free every week.
From the archive
Prompt Caching in the Claude API: A Production Guide
Apr 29, 2026 • 11 min read
RAG with Claude: Add Context Without Retraining
Apr 29, 2026 • 10 min read
SAM 3.1: Realtime Video Segmentation in Apps
Apr 29, 2026 • 10 min read
Self-Hosting AI Agents: 5 Ways to Run Claude Code on Your Own Infra
Apr 29, 2026 • 13 min read
Code-Level Migration
Here is the minimal-diff before/after for a single conversation turn. The "before" is the standard Assistants pattern most of us wrote in 2024:
// BEFORE - Assistants API
const thread = await client.beta.threads.create();
await client.beta.threads.messages.create(thread.id, {
role: "user",
content: userMessage,
});
const run = await client.beta.threads.runs.createAndPoll(thread.id, {
assistant_id: ASSISTANT_ID,
});
const messages = await client.beta.threads.messages.list(thread.id);
const reply = messages.data[0].content[0].text.value;
// AFTER - Responses API
const response = await client.responses.create({
model: "gpt-5.5",
instructions: SYSTEM_PROMPT,
input: userMessage,
tools: TOOLS,
previous_response_id: priorResponseId, // null on first turn
store: true, // 30-day server retention
});
const reply = response.output_text;
const newResponseId = response.id; // persist for next turn
The "after" version is shorter, synchronous on the happy path, and the conversation chain lives in two places you control: your DB row (the response.id) and your prompt repo (SYSTEM_PROMPT).
State and History Handling
This is where I lost the most time. Three patterns I now use:
Pattern 1: Short-lived chains (default). Persist previous_response_id against your conversation row. On each turn, pass it. Trust OpenAI's 30-day retention. This is what most apps want.
await db.conversation.update({
where: { id: convId },
data: { lastResponseId: response.id },
});
Pattern 2: Long-lived or compliance-bound chains. Do not rely on server retention. Store every message in your DB and pass them explicitly:
const response = await client.responses.create({
model: "gpt-5.5",
instructions: SYSTEM_PROMPT,
input: messages.map((m) => ({ role: m.role, content: m.content })),
store: false, // do not retain server-side
});
Pattern 3: Hybrid. Short-lived state via previous_response_id, but you also write every input/output to your DB for replay and eval purposes. This is what I run in production. It is the only pattern that gives you both ergonomic continuity and full-control debugging.
The cliff I hit: I assumed previous_response_id would still work after 31 days. It does not - the server returns a 404. Wrap every call in a fallback that reconstructs from your DB if the chain is missing.
Tool-Use Parity
Function calling works, with a flatter schema. The tools array is the same shape. The big differences:
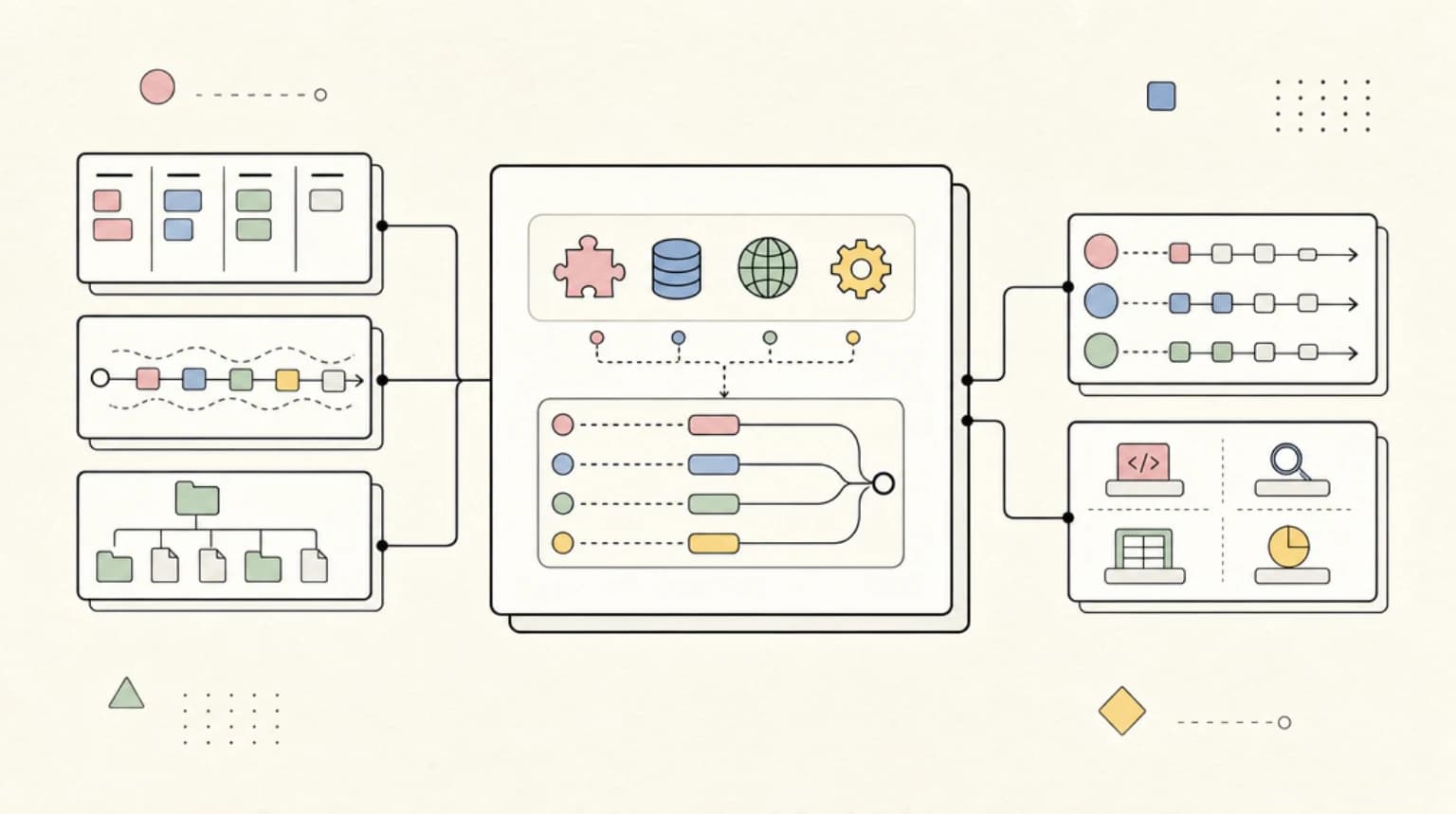
- Built-in tools.
code_interpreterandfile_searchare now first-class tools you enable per call. No more attaching them to an assistant. - Parallel tool calls. Default-on in Responses. If your old code assumed serial tool execution, audit your handlers - they will now fire in parallel.
- Streaming tool calls. You can stream tool-call deltas, which means you can render "agent is calling tool X..." in real time. Assistants forced you to wait for
requires_action.
Here is the parallel-tool gotcha. In Assistants, this code was safe:
// Assistants - implicit serial
for (const call of run.required_action.submit_tool_outputs.tool_calls) {
const output = await runTool(call); // safe, one at a time
}
In Responses, the model now expects you to handle multiple tool calls concurrently. If runTool is not idempotent or hits a rate-limited downstream, batch your calls or Promise.all them with a concurrency cap:
import pLimit from "p-limit";
const limit = pLimit(3);
const outputs = await Promise.all(
response.required_action.submit_tool_outputs.tool_calls.map((call) =>
limit(() => runTool(call))
)
);
I missed this on my first migration. The customer-support agent fired four parallel ticket-update calls to a legacy CRM and got rate-limited into oblivion within an hour.
Eval-Driven Cutover
The migration is mechanical but the behavior is not always identical. Different default temperatures, different tool-call patterns, different message-formatting quirks. I would not cut over without a regression eval.
My harness: a flag-gated rollout where 10% of traffic goes to Responses, 90% to Assistants, both runs are logged with the same input, and a nightly job scores the diffs. I open-sourced the bones of this as Agent Eval Bench - input replay, output diff, automated grading via a stronger model.
The cutover schedule that worked for me:
- Week 1 - Build the Responses path behind a feature flag. 0% traffic. Run shadow evals on logged inputs.
- Week 2 - 10% live traffic. Watch error rates, latency, customer-reported issues.
- Week 3 - 50% if metrics hold. Bug-fix anything weird.
- Week 4 - 100%. Keep the Assistants code path in the repo with
@deprecatedcomments for one more month, then delete.
Burn-down looked roughly like this in my logs:
Day 1: 47 endpoints calling Assistants
Day 7: 47 (built path, no traffic yet)
Day 9: 47 → 47 (10% rollout, both alive)
Day 14: 47 → 12 (cut the safe ones, kept stateful chains on assistants)
Day 21: 12 → 3 (long-lived chain edge cases)
Day 28: 0
The last three were the long-lived stateful chains where I needed pattern 2 above (explicit history). They took longer because I had to backfill DB writes for conversations that had been server-stateful for months.
What I Would Do Differently
Three things in priority order:
- Start with eval, not code. Get the harness running before you write a line of migration code. Without a regression signal you are migrating blind.
- Migrate stateless flows first. RAG queries, one-shot tool calls, summarization. These are mechanical search-and-replace. Build confidence before tackling stateful chains.
- Audit parallel tool calls explicitly. Do not assume. Grep your
runToolimplementations for shared mutable state. The parallel-by-default behavior will find every race condition you have.
Frequently Asked Questions
When is the Assistants API actually shutting down?
OpenAI publishes the current timeline on the platform deprecations page and updates it as the plan firms up. Treat the deprecations page as the source of truth, not social threads.
Can I keep using threads and runs?
Not long-term. The Responses API does not use the same thread and run primitives. The migration guide shows the mapping, but the conceptual shift is that state is either passed explicitly or chained via previous_response_id.
Does previous_response_id replace a database?
No. It is a continuity mechanism, not a storage strategy. For anything compliance-bound, long-lived, or audit-heavy, store your inputs and outputs in your own database and treat server retention as a convenience.
What is the safest migration strategy?
Run an eval harness before and after. Migrate one workload at a time, keep the old system behind a flag, and record enough receipts (inputs, outputs, tool calls, latency) to debug regressions quickly.
Do I need to change my tool calling code?
Probably. The Responses API expects parallel tool calls by default. If your tool handlers assume serial execution, add a concurrency cap and make idempotency explicit before you cut over.
OpenAI gave us through 2026, which sounds generous until you remember every other library you depend on is also moving. Do not be the one team migrating in October.
The Responses API is the better primitive. It is simpler, more honest about state, and the streaming model finally feels native. The migration is a weekend of work for a small codebase and two weeks for a complex one. Worth it.
Read next
Migrating to Claude Fable 5: The Practical Guide
Fable 5 is mostly a drop-in replacement for Opus 4.8, but 'mostly' is doing real work in that sentence. Here's every breaking change, what to delete from your code, and the prompt audit you should run before flipping the model ID.
9 min readGPT-5.5 for Developers: A Production Field Guide
GPT-5.5 and 5.5 Pro hit the API on April 24. Here is what changes for builders: pricing, agentic tasks, tool-use, and the real benchmarks I ran the day it dropped.
11 min readGemini CLI to Antigravity CLI Migration Guide: The June 18 Deadline
Gemini CLI stops working June 18, 2026. Here is exactly what to do: install Antigravity CLI, migrate your config, update your scripts, and avoid the silent MCP failure that breaks tool calls.
7 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI Coding
Droid
Factory AI's terminal coding agent. Runs Anthropic and OpenAI models in one subscription. Handles full tasks end-to-end...
View ToolAI FrameworksEssential
Vercel AI SDK
The TypeScript toolkit for building AI apps. Unified API across OpenAI, Anthropic, Google. Streaming, tool calling, stru...
View ToolAI Models
OpenRouter
Unified API for 200+ models. One API key, one billing dashboard. OpenAI, Anthropic, Google, Meta, Mistral, and more. Aut...
View ToolAI Models
GPT-5
OpenAI's latest flagship model. Major leap in reasoning, coding, and instruction following over GPT-4o. Powers ChatGPT P...
View ToolApps from Developers Digest
Developer ToolsIn Progress
Migrate
Beat the August 2026 Assistants API sunset. Paste old code, get Responses API.
View AppDeveloper ToolsIn Progress
API Docs Kit
Turn API documentation and OpenAPI specs into typed SDK plans and demo checklists.
View AppDeveloper ToolsIn Progress
Docs To Demo
Turn API docs into endpoint maps, auth setup, demo ideas, and build-ready prompts.
View AppRelated Guides
Guide
Claude Code Setup Guide
Configure Claude Code for maximum productivity -- CLAUDE.md, sub-agents, MCP servers, and autonomous workflows.
AI AgentsGuide
Building Your First MCP Server
Step-by-step guide to building an MCP server in TypeScript - from project setup to tool definitions, resource handling, testing, and deployment.
AI AgentsGuide
Chronicle Research Preview Setup Guide
Set up Codex Chronicle on macOS, manage permissions, and understand privacy, security, and troubleshooting.
Getting StartedRelated Posts
9 min read
Claude
Migrating to Claude Fable 5: The Practical Guide
Fable 5 is mostly a drop-in replacement for Opus 4.8, but 'mostly' is doing real work in that sentence. Here's every bre...
8 min read
Codex
Codex-Maxxing: How to Run Long-Running Codex Workflows Without Losing the Plot
Codex-Maxxing should mean bounded autonomy: AGENTS.md, small worktrees, explicit stop conditions, subagents only when wo...
8 min read
OpenAI
OpenAI Agent Builder and Evals Are Shutting Down: Move the Agent Stack Into Code
OpenAI's June deprecations put Agent Builder, hosted Evals, and reusable prompts on a November 30 shutdown path. Here is...

8 min read
OpenAI
OpenAI Daybreak Shows the AppSec Bottleneck Is Patching, Not Finding
OpenAI's Daybreak and Patch the Planet point at the real agentic AppSec shift: security agents only matter when they pro...
5 min read
News
Codex Logging Bug Can Write Terabytes to Your SSD
A bug in OpenAI's Codex CLI writes excessive trace logs to SQLite, potentially consuming 640TB/year of SSD writes. The i...
5 min read
News
Noam Shazeer Joins OpenAI After Two Years Back at Google
The Transformer co-creator leaves Google DeepMind for OpenAI just two years after Google paid $2.7 billion to bring him...

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever